
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 장치 초기화
- gitlab
- Deferred Rendering
- 네트워크 게임 프로그래밍
- Dynamic Indexing
- Frustum Culling
- 디퍼드 렌더링
- 입방체 매핑
- FrameResource
- 동적 색인화
- 직교 투영
- InputManager
- C++
- 절두체 컬링
- gitscm
- 노멀 맵핑
- 네트워크
- Direct3D12
- light
- 게임 프로그래밍
- Render Target
- effective C++
- 게임 클래스
- 큐브 매핑
- 게임 디자인 패턴
- TCP/IP
- DirectX12
- direct3d
- DirectX
- 조명 처리
- Today
- Total
코승호딩의 메모장
[멀티스레드] 본문
01 스레드 기초
이번 글에서는 다수의 클라이언트를 독립적으로 처리하는 멀티스레드 기법을 사용한다. 이 전에 작성한 예제에서는 두 개 이상의 클라이언트가 서버에 접속할 수 있지만 서버가 동시에 두 개 이상 클라이언트를 서비스할 수 없다는 문제가 있으며 서버와 클라이언트의 send, recv함수 호출 순서가 맞아야 한다는 문제가 있다. 데이터를 보내지 않은 상태에서 양쪽에서 동시에 recv 함수를 호출하면 교착 상태가 발생할 수 있다. 결국 두 프로세스는 recv 함수에서 빠져나가지 못하게 된다.
서버가 동시에 두 개 이상 클라이언트를 서비스할 수 없다는 문제
- 해결책 1: 서버가 각 클라이언트와 연결하여 통신하는 시간을 짧게 줄인다. 즉, 클라이언트가 데이터를 전송하기 전에 매번 서버에 접속하고 전송 후 바로 접속을 끊는 방식을 사용한다. 이 방법은 쉽게 구현이 가능하며 서버의 시스템 자원을 적게 사용하지만 파일 전송 프로그램과 같은 대용량 데이터 전송 프로그램에는 적합하지 않다. 또한 클라이언트 수가 많아지면 처리 지연 시간이 길어질 수 있다.
- 해결책 2: 서버에 접속한 클라이언트마다 스레드를 생성하여 독립적으로 처리한다. 이 방법은 소켓 입출력 모델에 비해 쉽게 구현할 수 있지만 접속한 클라이언트 수에 비례해 스레드를 생성하기에 서버의 시스템 자원을 많이 사용한다.
- 해결책 3: 소켓 입출력 모델을 사용한다. 이 방법은 소수의 스레드를 이용하여 다수의 클라이언트를 처리할 수 있으며 서버의 시스템 자원을 적게 사용하지만 다른 두 방법보다 구현이 어렵다.
서버와 클라이언트의 send, recv함수 호출 순서가 맞아야 한다는 문제
- 해결책 1: 데이터 송수신 부분을 잘 설계하여 교착 상태가 발생하지 않도록 한다. 이 방법은 특별 기법 없이 구현할 수 있지만 데이터 송수신 패턴이 달라지면 교착 상태가 발생할 수 있어 모든 상황에 적용이 어렵다.
- 해결책 2: 소켓에 타임아웃 옵션을 적용하여, 소켓 함수 호출 시 작업이 완료되지 않아도 일정 시간 이후 리턴하게 한다. 이 방법은 비교적 간단하지만 다른 방법보다 성능이 떨어진다. 타임 아웃으로 지정한 시간이 지날 때까지 아무것도 할 수 없기 때문이다.
- 해결책 3: 넌블로킹 소켓을 사용한다. 이 방법은 조건을 만족하지 않더라도 소켓 함수가 즉시 리턴하여 교착 상태를 막을 수 있지만 구현이 복잡하며 CPU 시간을 불필요하게 낭비할 수 있다.
- 해결책 4: 소켓 입출력 모델을 사용한다. 이 방법은 넌블로킹 소켓의 단점을 보완하며 교착 상태를 막을 수 있고 일관성 있게 구현할 수 있지만 구현이 어렵다.
프로세스란 CPU 시간을 할당받아 실행 중인 프로그램을 말한다. 프로그램은 저장 장치에 실행 파일로 존재하는 정적인 개념이지만 프로세스는 코드, 데이터, 리소스를 파일에서 읽어 작업을 수행하는 동적인 개념이다.
윈도우 운영체제에서는 프로세스 개념을 프로세스와 스레드 두 가지로 구분한다. 프로세스는 코드, 데이터, 리소스를 파일에서 읽어 들여 메모리 영역에 담고 있는 일종의 컨테이너이며 스레드는 CPU 시간을 할당받아 프로세스 메모리 영역에 있는 코드를 수행하고 데이터를 사용하는 실행 흐름으로 동적인 개념이다. 따라서 일반 운영체제 프로세스는 프로세스 + 스레드이다.
응용 프로그램이 CPU 시간을 할당받아 실행하려면 한 개 이상의 스레드가 필요하다. 응용 프로그램 실행 시 최초 생성되는 스레드가 주 스레드 혹은 메인 스레드라고 부른다. main 함수 또는 WinMain 함수에서 실행을 시작하며 별도 작업을 하기 위해서는 스레드를 추가로 생성하여 해당 작업을 수행하도록 시켜야 한다. 이러한 형태의 프로그램을 멀티스레드 응용 프로그램이라 한다.
CPU 하나가 스레드 두 개를 동시에 실행할 수는 없지만 교대로 실행하여 사용자가 동시에 두 스레드가 실행되는 것처럼 느끼게 할 수는 있다. 이를 위해서는 각 스레드 최종 실행 상태를 저장하고 나중에 복원하는 작업을 반복해야 한다. 스레드의 실행 상태란 CPU와 메모리 상태를 말하며 구체적으로는 CPU 레지스터 값과 메모리의 스택을 의미한다. 이러한 스레드 실행 상태의 저장과 복원을 CPU와 운영체제의 협동으로 이루어지는 컨텍스트 전환이라고 부른다.

위 그림은 하나의 프로세스가 두 개의 스레드를 사용하는 원리를 보여준다. 우선 (a)에서 스레드 1이 실행 중이다. 명령 하나 수행할 때마다 CPU 레지스터 값과 메모리의 스택 내용이 변경된다. (b)에서 스레드 1을 중지하고 실행 상태를 저장한다. 스택은 메모리에 계속 유지된다. 그리고 이전에 저장해 둔 스레드 2를 복원한다. (c)에서 스레드 2를 실행한다. 명령을 수행할 때마다 CPU 레지스터 값과 메모리 스택 내용이 변경된다. (d)에서 스레드 2의 실행을 중지하고 실행 상태를 저장한 다음 이전 저장해 둔 스레드 1의 상태를 복원한다. (e)에서 스레드 1을 다시 실행한다. 이전 실행 상태를 복원하였기 때문에 스레드 1은 마지막에 수행했던 명령의 다음 위치부터 진행한다.

리소스 모니터를 실행하면 다음 그림과 같이 스레드를 두 개 이상으로 사용하는 프로그램이 많다는 것을 확인할 수 있다.
02 스레드 API
스레드를 응용 프로그램에서 구현하기 위해서는 윈도우 운영체제가 제공하는 API를 사용해야 한다.

위 그림은 함수 두 개로 구성된 응용 프로그램에 스레드 세 개가 존재하는 상황이다. 프로세스가 생성되면 main 함수를 실행 시작점으로 하는 메인 스레드가 자동으로 생성된다. 또 다른 함수 f를 실행 시작점으로 하는 스레드를 생성하기 위해서 운영체제에 아래의 정보를 제공해야 한다.
- f 함수의 시작 주소 : 운영체제는 f 함수의 시작 주소를 알아야 한다. C/C++ 프로그램에서는 함수 이름이 곧 함수의 시작 주소를 의미하므로 f 함수와 같이 스레드 실행 시작점이 되는 함수를 스레드 함수라고 한다.
- f 함수 실행 시 사용할 스택의 크기 : C/C++ 프로그램의 모든 함수는 실행 중 인수 전달과 변수 할당을 위해 스택이 필요하다. 만약 f 함수에서 두 개의 스레드를 실행하고자 한다면 서로 다른 메모리 위치에 스택을 두 개 할당해야 한다. 스레드 실행에 필요한 스택 생성은 운영체제가 자동으로 해주기 때문에 스택 크기만 알려주면 된다.
윈도우에서 스레드를 생성할 때는 CreateThread 함수를 사용한다. 이 함수는 스레드를 생성한 후 스레드 핸들을 반환한다. 스레드 핸들은 운영체제의 스레드 관련 데이터 구조체를 간접적으로 참조한다. 스레드 핸들을 API 함수에 전달하여 스레드를 제어한다.

- lpThreadAttributes : 기본값인 NULL을 사용하면 스레드를 생성하고 활용하는 데 문제가 없다.
- dwStackSize : 스레드에 할당되는 스택 크기(바이트 단위)이다. 0을 사용하면 실행 파일의 헤더에 들어 있는 기본 크기를 사용하는데, C++ 응용 프로그램에서는 옵션을 변경하지 않으면 기본 크기는 1MB이다.
- lpStartAddress : 스레드 함수의 시작 주소이다. 스레드 함수 이름은 자유롭게 하되 반드시 DWORD WINAPI ThreadProc(LPVOID lpParameter)과 같은 형태로 입력과 출력 타입을 정의해야 한다.
- lpParameter : 스레드 함수에 전달할 인수다. 포인터 크기보다 큰 데이터는 값을 구조체나 배열에 넣고 반드시 주소 형태로 전달해야 한다. 전달할 주소가 없다면 NULL 값을 넣어준다. 같거나 작다면 값이나 주소 형태로 전달이 가능하다.
- dwCreationFlags : 스레드 생성을 제어하는 값으로 0 또는 CREATE_SUSPENDED를 사용한다. 0은 스레드 생성 후 곧바로 실행되고, CREATE_SUSPENDED는 스레드가 생성은 되지만 ResumeThread 함수 호출 전까지 실행되지 않는다.
- lpThread : DWORD형 변수를 전달하면 스레드 ID가 저장된다. 스레드 ID가 필요 없으면 NULL 값을 전달한다.
윈도우에서 스레드를 종료하는 방법은 총 네 가지가 있다. 스레드 함수가 리턴하거나 스레드 함수 안에서 ExitThread 함수를 호출하거나 TerminateThread 함수를 호출하여 스레드를 강제 종료하거나 메인 스레드가 종료하면 프로세스 내의 다른 모든 스레드가 강제 종료된다.

일반적으로는 첫 번째와 두 번째 방법을 통해 스레드를 종료하는 것이 바람직하며 세 번째는 꼭 필요한 경우에만 사용해야 하며 마지막 방법은 메인 스레드의 특성이다.
DWORD WINAPI f(LPVOID arg)
{
//...
return 0;
}
int main()
{
//...
// 첫 번째 스레드 생성
HANDLE hThread1 = CreateThread(NULL, 0, f, NULL, 0, NULL);
if (hThread1 == NULL) 오류 처리;
// 첫 번째 스레드 생성
HANDLE hThread2 = CreateThread(NULL, 0, f, NULL, 0, NULL);
if (hThread2 == NULL) 오류 처리;
}위 코드는 위에서 배운 내용을 토대로 스레드 생성과 종료를 보여준다.
int main(int argc, char *argv[])
{
// 첫 번째 스레드 생성
Point3D pt1 = { 10, 20, 30 };
HANDLE hThread1 = CreateThread(NULL, 0, MyThread, &pt1, 0, NULL);
if (hThread1 == NULL) return 1;
CloseHandle(hThread1);
// 두 번째 스레드 생성
Point3D pt2 = { 40, 50, 60 };
HANDLE hThread2 = CreateThread(NULL, 0, MyThread, &pt2, 0, NULL);
if (hThread2 == NULL) return 1;
CloseHandle(hThread2);
printf("Running main() %d\n", GetCurrentThreadId());
Sleep(2000);
return 0;
}위 코드는 Point3D 라는 점 3개의 위치 정보를 가진 구조체를 만들어서 두 개의 스레드를 생성하여 위치 정보를 출력하는 함수이다. 메인 함수에서 마지막 Sleep(2000)의 지연 시간이 함수 내 Sleep(1000)보다 작아지거나 없다면 메인 함수가 더 빨리 리턴하게 될 수 있어 출력이 되지 않는 경우가 있으므로 추가한다.
윈도우 운영체제에서는 여러 스레드가 CPU 시간을 사용하기 위해 경쟁한다. 따라서 각 스레드에 CPU 시간을 적절히 분배하기 위한 정책인 CPU 스케줄링을 사용한다. 스케줄링 기법은 우선순위에 기반한 것으로 우선순위가 높은 스레드에 먼저 CPU 시간을 할당한다. 스레드의 우선순위를 결정하는 요소는 다음과 같다.=
- 프로세스 우선순위 : 우선순위 클래스라고 부른다.
- 스레드 우선순위 : 우선순위 레벨이라고 부른다.
우선순위 클래스는 프로세스 속성으로 한 프로세스가 생성한 스레드는 우선순위 클래스가 모두 같다는 특징이 있다.
- REALTIME_PRIORITY_CLASS(실시간)
- HIGH_PRIORITY_CLASS(높음)
- ABOVE_NORMAL_PRIORITY_CLASS(높은 우선순위)
- NORMAL_PRIORITY_CALSS(보통)
- BELOW_NORMAL_PRIORITY_CLASS(낮은 우선순위)
- IDLE_PRIORITY_CLASS(낮음)

작업 관리자의 세부 정보에서는 다음과 같이 프로세스의 우선순위 클래스를 다른 값으로 변경할 수 있다.
우선순위 레벨은 스레드 속성으로, 같은 프로세스에 속한 스레드 간에 상대적인 우선순위를 결정할 때 사용한다.
- THREAD_PRIORITY_TIME_CRITICAL
- THREAD_PRIORTY_HIGHEST
- THREAD_PRIORITY_ABOVE_NORMAL
- THREAD_PRIORITY_NORMAL
- THREAD_PRIORITY_BELOW_NORMAL
- THREAD_PRIORITY_LOWEST
- THREAD_PRIORITY_IDLE
우선순위 클래스와 우선순위 레벨을 결합하면 스레드 기본 우선순위가 결정되고 이 값이 스레드 스케줄링에 사용된다. 윈도우에서는 우선순위가 가장 높은 스레드에 CPU 시간을 할당하지만 우선순위가 같다면 번갈아 할당한다.

위 그림은 우선순위 클래스와 우선순위 레벨에 따른 스레드 스케줄링이다. 그러나 이러한 방식에서는 우선순위가 높은 스레드가 계속 CPU 시간을 요구하면 낮은 스레드는 CPU 시간을 전혀 할당받지 못하는 기아문제가 생긴다. 이를 해결하기 위해서 CPU 시간을 할당받지 못한 스레드의 우선순위를 단계적으로 끌어올린다. 이렇게 우선순위가 낮은 스레드도 CPU를 사용할 수 있도록 한다. 또한 현재 사용하고 있는 프로그램의 속도를 빠르게 하기 위해 우선순위를 동적으로 변경하기도 한다.
멀티스레드를 이용할 때는 작업 중요도에 따라 응용 프로그램이 직접 우선순위를 변경하기도 하는데 우선순위 클래스를 변경하는 경우는 흔치 않으며 대개 우선순위 레벨을 변경한다. 클릭한 윈도우의 우선순위가 높아지고 뒤로 밀리는 프로세스들은 우선순위가 낮아지는데 이는 운영체제가 알아서 해주는 일이다. 또한 우선순위를 높인다고 항상 먼저 실행되는 개념이 아니라 실행될 확률이 올라가는 것이다.

위 함수들은 우선순위 레벨을 변경하는 함수와 현재의 우선순위 레벨을 가져오는 함수이다.
DWORD WINAPI MyThread(LPVOID arg)
{
while (1);
return 0;
}
int main()
{
// 우선순위 값의 범위를 출력한다.
printf("우선순위: %d ~ %d\n", THREAD_PRIORITY_IDLE,
THREAD_PRIORITY_TIME_CRITICAL);
// CPU 개수를 알아낸다.
SYSTEM_INFO si;
GetSystemInfo(&si);
// CPU 개수만큼 스레드를 생성한다.
for (int i = 0; i < (int)si.dwNumberOfProcessors; i++) {
// 스레드를 생성한다.
HANDLE hThread = CreateThread(NULL, 0, MyThread, NULL, 0, NULL);
// 우선순위를 높게 설정한다.
SetThreadPriority(hThread, THREAD_PRIORITY_ABOVE_NORMAL);
CloseHandle(hThread);
}
// 우선순위를 낮게 설정한다.
SetThreadPriority(GetCurrentThread(), THREAD_PRIORITY_BELOW_NORMAL);
Sleep(1000);
printf("주 스레드 실행!\n");
return 0;
}위 코드는 메인 스레드 외 새로운 스레드를 CPU 개수만큼 생성하고 우선순위 레벨을 변경하는 응용 프로그램이다. 우선 CPU 개수만큼 생성한 MyThread의 우선순위 레벨을 메인 스레드보다 높게 설정하고 무한 루프를 돌며 CPU 시간을 계속 요구한다. 만약 우선순위가 고정되어 있다면 MyThread만 CPU를 사용하게 되며 기아가 발생할 수 있지만 윈도우 운영체제에서는 오랜 시간 CPU 시간을 할당받지 못한 스레드의 우선순위를 동적으로 단계적으로 끌어올리기 때문에 메인 스레드도 실행할 기회를 얻고 결국 무한 루프를 나가게 된다.
스레드는 생성되면 CPU 시간을 사용하기 위해서 다른 스레드와 경쟁하며 독립적으로 실행된다. 하지만 때로는 한 스레드의 종료 여부를 확인해야 할 때가 있다. 이때 WaitForSingleObject 함수를 사용하면 특정 스레드가 종료할 때까지 기다린다.


WAIT_OBJECT_0을 반환받으면 작업이 끝났음을 의미하고 WAIT_TIMEOUT은 작업이 아직 끝나지 않은 경우이다. 첫 번째 인자에 넘겨준 대상 스레드를 두 번째 인자로 넘겨준 대기 시간 안에 종료하지 않으면 WaitForSingleObject 함수를 리턴하는 것이다. 만약 대기 시간으로 INFINITE 값을 사용하면 스레드가 종료할 때까지 무한히 기다린다.
여러 스레드가 종료하기를 기다리기 위해서는 WaitForMultipleObjects 함수를 사용한다.


이 함수를 사용할 때는 스레드 핸들을 배열에 넣어 전달하며 배열 요소의 개수와 배열의 시작 주소를 전달한다. nCount의 최댓값은 MAXIMUM_WAIT_OBJECTS(=64)로 정의되어 있다. 두 번째 인자는 TRUE이면 모든 스레드가 종료할 때까지 기다리며 FALSE이면 한 스레드가 종료하는 즉시 리턴한다.

위 코드는 어떠한 스레드가 종료되었는지를 리턴 값으로 받아서 처리할 수 있는 것을 보여준다.
스레드 핸들을 보유하고 있다면 SuspendThread 함수를 호출하여 해당 스레드 실행을 일시 중지하거나 재시작할 수 있다. 윈도우 운영체제는 스레드 중지 횟수를 관리하는데 이 값은 SuspendThread 함수를 호출할 때마다 1씩 증가하고 ResumeThread 함수를 호출할 때마다 1씩 감소한다. 중지 횟수가 0보다 크다면 스레드는 실행 중지 상태인 것이다. 따라서 SuspendThread 함수를 두 번 호출했다면 ResumeThread 함수를 두 번 호출해야 재시작할 수 있다.

int sum = 0;
DWORD WINAPI MyThread(LPVOID arg)
{
int num = (int)(long long)arg;
for (int i = 1; i <= num; i++)
sum += i;
return 0;
}
int main(int argc, char *argv[])
{
int num = 100;
HANDLE hThread = CreateThread(NULL, 0, MyThread,
(LPVOID)(long long)num, CREATE_SUSPENDED, NULL);
printf("스레드 실행 전. 계산 결과 = %d\n", sum);
ResumeThread(hThread);
WaitForSingleObject(hThread, INFINITE);
printf("스레드 실행 후. 계산 결과 = %d\n", sum);
CloseHandle(hThread);
return 0;
}위 코드는 스레드를 이용하여 1부터 100까지 합을 구해준다. CreateThread를 사용하여 스레드를 생성할 때, CREATE_SUSPENDED를 넣어줬기 때문에 ResumeThread 함수를 사용해야 함수가 재시작된다. 그리고 스레드가 계산을 완료했는지 확인하기 위한 WaitForSingleObject가 있다.
참고로 Sleep 함수를 호출하면 자신에게 할당된 CPU 시간을 포기하고 남은 시간을 우선순위가 같은 다른 스레드에게 넘겨준다. 이를 이용하면 빠르게 컨텍스트 전환을 할 수 있다.
03 멀티스레드 TCP 서버
이제 멀티스레드를 이용하여 여러 클라이언트를 동시에 처리할 수 있는 TCP 서버를 작성해보자. 그 전에 스레드 함수에 소켓만 전달한 경우 별도의 주소 정보가 없으므로, 소켓 자체에서 주소 정보를 얻는 기능이 필요하다. 다음 함수를 알아보자.
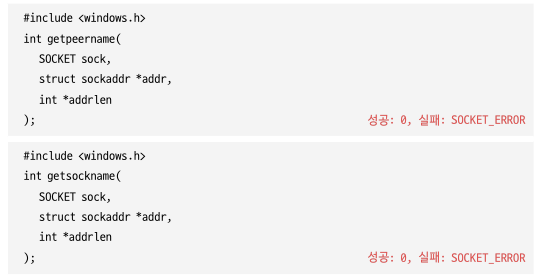
getpeername 함수는 소켓 데이터 구조체에 저장된 원격 IP 주소와 원격 포트 번호를 리턴한다. 그리고 getsockname 함수는 소켓 데이터 구조체에 저장된 지역 IP 주소와 지역 포트 번호를 리턴한다.
DWORD WINAPI ProcessClient(LPVOID arg)
{
int retval;
SOCKET client_sock = (SOCKET)arg;
struct sockaddr_in clientaddr;
char addr[INET_ADDRSTRLEN];
int addrlen;
char buf[BUFSIZE + 1];
// 클라이언트 정보 얻기
addrlen = sizeof(clientaddr);
getpeername(client_sock, (struct sockaddr *)&clientaddr, &addrlen);
inet_ntop(AF_INET, &clientaddr.sin_addr, addr, sizeof(addr));
while (1) {
// 데이터 받기
retval = recv(client_sock, buf, BUFSIZE, 0);
if (retval == SOCKET_ERROR) {
err_display("recv()");
break;
}
else if (retval == 0)
break;
// 받은 데이터 출력
buf[retval] = '\0';
printf("[TCP/%s:%d] %s\n", addr, ntohs(clientaddr.sin_port), buf);
// 데이터 보내기
retval = send(client_sock, buf, retval, 0);
if (retval == SOCKET_ERROR) {
err_display("send()");
break;
}
}
// 소켓 닫기
closesocket(client_sock);
printf("[TCP 서버] 클라이언트 종료: IP 주소=%s, 포트 번호=%d\n",
addr, ntohs(clientaddr.sin_port));
return 0;
}위 코드는 멀티스레드에서 각 스레드마다 호출해야 할 스레드 함수에 해당한다. 스레드 함수에서는 이전 예제와 똑같이 클라이언트의 주소 정보를 저장하여 클라이언트가 보낸 데이터를 출력하고 다시 클라이언트로 보내준다.
int main(int argc, char *argv[])
{
// 윈속 초기화
// 소켓 생성
// bind()
// listen()
// 데이터 통신에 사용할 변수
while (1) {
// accept()
// 접속한 클라이언트 정보 출력
// 스레드 생성
hThread = CreateThread(NULL, 0, ProcessClient,
(LPVOID)client_sock, 0, NULL);
if (hThread == NULL) { closesocket(client_sock); }
else { CloseHandle(hThread); }
}
// 소켓 닫기
// 윈속 종료
}메인 함수에서는 이전 예제와 크게 다를 것이 없다. 만약 클라이언트가 접속하였다면 이 클라이언트에 해당하는 스레드를 새로 생성하여 스레드 함수를 호출한다.
'네트워크 프로그래밍' 카테고리의 다른 글
| [데이터 전송하기] (0) | 2023.09.27 |
|---|---|
| [TCP 서버-클라이언트] (0) | 2023.09.26 |
| [소켓 주소 구조체] (0) | 2023.09.12 |
| [소켓 시작하기] (0) | 2023.09.10 |
| [네트워크와 소켓 프로그래밍] (0) | 2023.09.09 |



